고정 헤더 영역
상세 컨텐츠
본문

TABLE FULLSCAN : 메모리(데이터베이스 버퍼캐시)에 없을때 DISK에서 모든 자료를 찾아서 조회하는 것
INDEX SCAN : 주소를 저장해놓고 어느 블록에 있는지 빠르게 가져오는 것
인덱스 작동원리 (일반) : 데이터 불러오기 -> PGA(정렬) -> 인덱스 파일에 블록순서대로 기록하기
—
인덱스 동작원리 (b-tree)
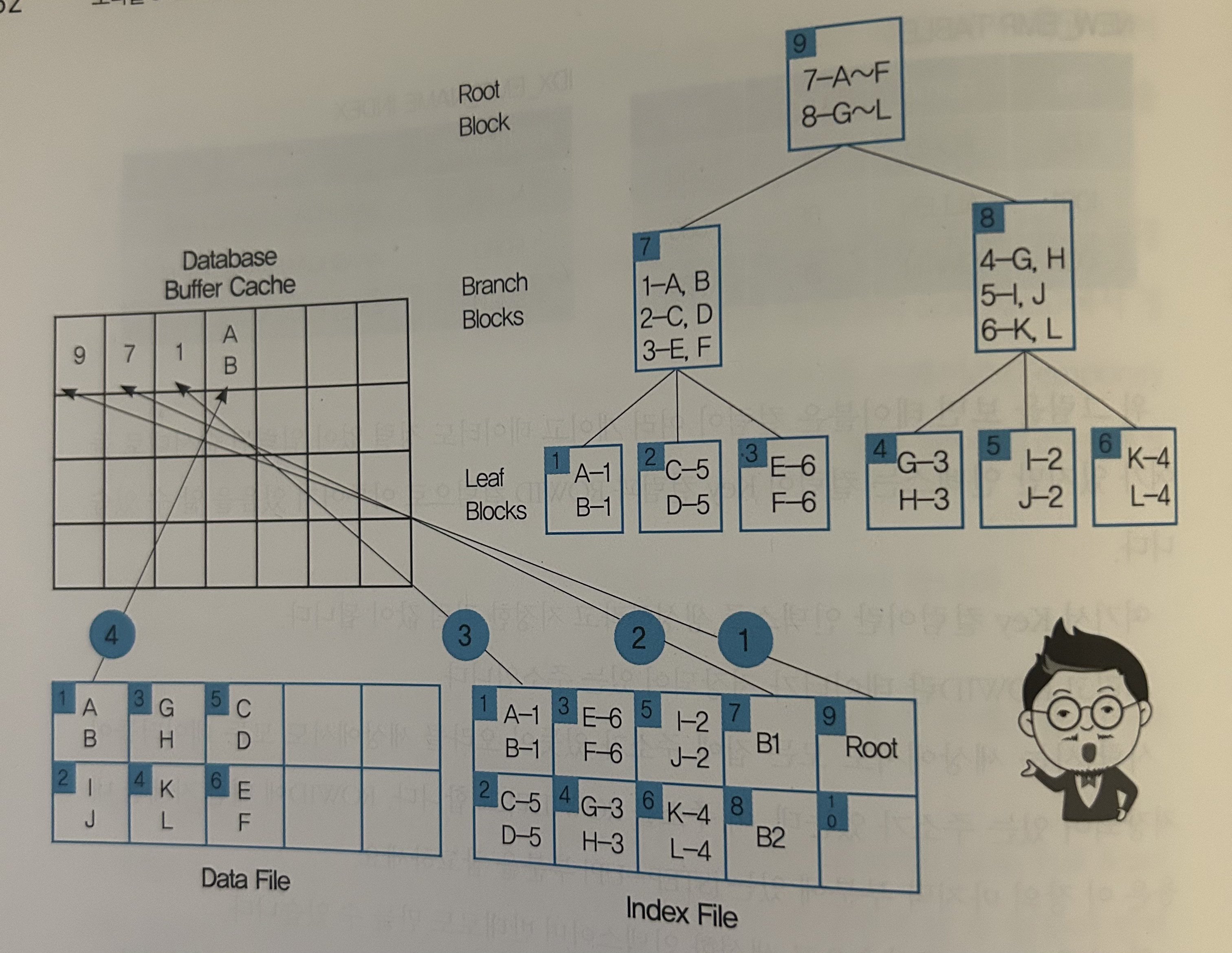
오라클은 가장 먼저 메모리의 데이터베이스 버퍼캐시에서 해당 데이터가 있는지를 먼저 살펴봅니다. 만약 데이터베이스 버퍼 캐시에 A가 있을 경우는 A를 요청한 사람에게 바로 보내주면 끝나지만 A가 없을 경우에는 하드 디스크의 Data File에 가서 해당 데이터를 Database Buffer Cache로 가져온 후 사용자에게 보내야 합니다. 하드 디스크의 Data File에서 원하는 블록을 찾아서 Database Buffer Cache로 복사해 올 때 바로 인덱스가 필요합니다.
ROOT블록부터 인덱스 파일에 있는것 확인> 데이터버퍼캐쉬로 이동> 해당 블록에대한 인덱스 파일 블록확인 > 데이터버퍼캐쉬로 이동 > 리프블록까지 반복
—.—
Single Block I/O
= 인덱스를 사용하여 여러 데이터를 조회할 경우에 한번에 하나의 블록만 읽을수있다.
Multi Block I/O
= 인덱스를 사용하지 않는 경우 여러블록을 한꺼번에 가져올 수 있다.
OLTP ( OnLine Transaction Processing ) - 실시간 트랜잭션 처리용 ,데이터 처리 시스템
OLAP ( OnLine Analytical Processing ) - 온라인 데이터 분석 처리용, 데이터 처리 시스템, 대량의 데이터를 한번에 입력한 후에 분석 통계정보를 출력할때 사용하는 환경
OLTP는 주로 B-Tree 인덱스 사용, OLAP는 주로 BITMAP인덱스 사용
—.—
Unique index
키값의 중복이 없다는 가정하에 인덱스를 생성한다. 현재는 물론 앞으로도 중복된 데이터는 들어올 수 없다.
```
CREATE UNIQUE INDEX 인덱스명
ON 테이블이름 (컬럼명1 ASC | DESC, 컬럼명 2, …)
‘’’
Non-Unique Index
키값의 중복을 허용하는 인덱스이다.
```
CREATE INDEX idx_dept2_area
ON dept2(area);
```
Function Based INDEX(FBI, 함수기반 인덱스)
Index Suppressing Error( 인덱스는 잘 작성해놓고 SQL을 잘못 작성해서 인덱스를 사용할 수 없는 경우) > 컬럼에 직접 연산 후 비교, Not 비교
>> 인덱스를 사용하려면 WHERE절의 조건을 절대로 다른 형태로 가공해서 사용하면 안된다.
Where pay + 100 = 9000이라는 조건절은 pay컬럼값을 기준으로 인덱스를 활용하는것이 불가능하다. 그런데 그럴만한 이유가 있는 경우 pay + 100을 기준으로 인덱스를 설정할 수도 있다.
```
CREATE INDEX idx_prof_pay_fbi
ON professor(pay+1000);
```
DESCENDING INDEX(내림차순 인덱스)
내림차순으로 자료를 정렬하여 인덱스를 생성하는 것, 필요시 쓰기 나름이지만 오름차순 인덱스도 존재하고 내림차순 인덱스도 존재하면 DML성능에 악영향을 끼칠수도 있다. 그래서 오라클에서는 힌트를 제공하여 자료순은 고정하고 위에서부터 읽는 효과, 아래에서부터 읽는 효과를 내기도 한다.
COMPOSITE INDEX(결합 인덱스)
인덱스를 생성할 때 두개 이상의 컬럼을 합쳐서 인덱스를 만드는 것, 여기서는 조건문의 두 조건이 AND로 결합될때에는 인덱스를 만드는 것을 생각할수 있으나 OR로 연결된다면 인덱스를 만들면 안된다.
그리고 컬럼을 동시에 만족하는 인덱스를 생성한다는 것은 컬럼A->컬럼B의 순서가 적절할지 컬럼B->컬럼A로 검색하는 것이 적절할지 고민해야된다. (e.g. (이름,성별)결합인덱스 vs (성별,이름)결합인덱스)
> 대출번호, 지점, 날짜 vs 날짜_필수, 대출번호, 지점
> 날짜, 대출번호 > 빨라짐? ㅇ
> 날짜, 지점 > 빨라짐? ㅇ
BITMAP INDEX
‘사원이 1000명이라 하더라도 성별 컬럼의 값의 종류는 2가지 뿐이므로 이곳은 BITMAP INDEX가 B-TREE INDEX보다 적당하다는 의미입니다.’
데이터를 0/1로 표현하여 보관한 다음 인덱스를 생성하기 때문에 데이터가 추가가 되거나 변경이 되면 기존 데이터 이외에도 다른 데이터의 비트값을 수정해줘야 한다. 따라서 B-TREE인덱스는 데이터를 변경할때 관련블록만 변경하면 되지만 BITMAP INDEX는 블록단위로 Lock을 설정하기 때문에 같은 블록에 들어있는 다른 데이터도 수정작업이 안되는 경우가 있다. -> BITMAP INDEX는 데이터가 변경이 안되는 테이블과 값의 종류가 작은 컬럼에 생성하는 것이 유리하다.
# 인덱스 생성시 단점
- DML에 취약하다
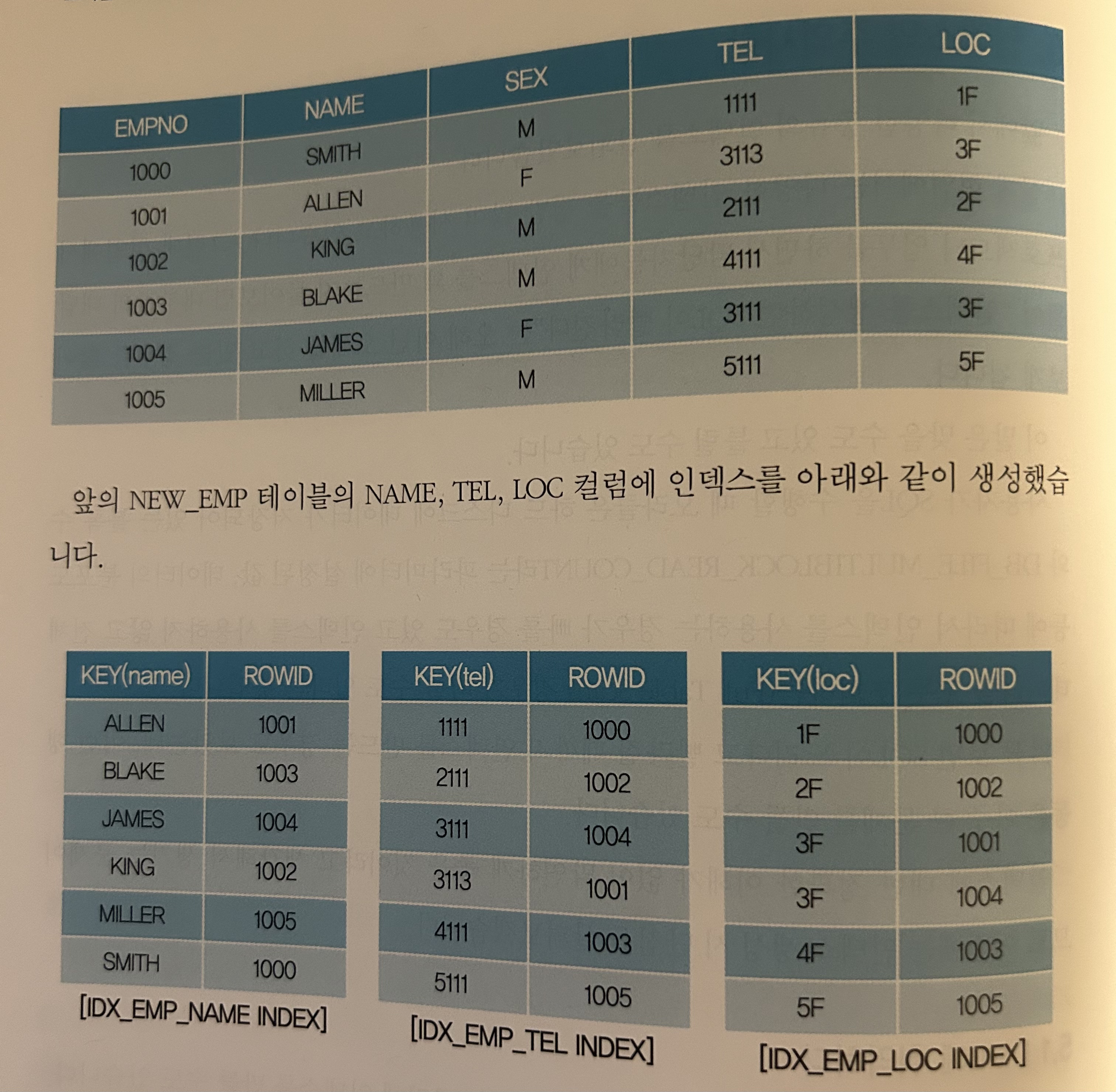
위와 같은 테이블과 인덱스가 존재할때 [1006, JOHN, M, 3112, 3F] 가 입력된다면 중간에 데이터가 끼어들어야 정렬이 되는 상황, index split발생 (하나의 블록에 저장되어 있던 데이터들이 빈자리가 없어서 2개의 블록으로 옮겨지게 되는 현상)
또한 delete되는 데이터 발생시 index에서는 미사용된다고 표시된다. 이러면 데이터가 지워질때 인덱스에서는 데이터가 안지워지고 데이터가 1만건인데 인덱스는 10만건이 될수도 있다는 말이다. 인덱스를 사용함에도 불구하고 쿼리의 수행속도가 아주 느려짐.
update될 경우에는 인덱스에서는 delete가 먼저 발생한 다음 새로운 데이터가 insert되는 작업이 발생한다. 즉, update는 delete와 insert의 영향이 동시에 발생하는 것이라서 인덱스에 큰 부하를 준다.
- 타 SQL실행에 악영향을 줄 수 있다(새로운 인덱스를 생성했을때 갑자기 느려지면?)
옵티마이저가 실행계획을 세울때 기존에 없었던 인덱스가 갑자기 테이블에 생기면 더 최근에 만들어진 인덱스가 더 좋을 것이라고 생각해서 잘 되고 있던 실행계획을 바꾸기 때문이다.
인덱스 관리 방법
- 인덱스 조회하기
SELECT table_name, index_name
FROM user_indexes
WHERE table_name=‘DEPT2’- 사용여부 모니터링하기
ALTER INDEX IDX_EMP_ENAME MONITORING USAGE; -- 모니터링 시작
ALTER INDEX IDX_EMP_ENAME NOMONITORING USAGE; -- 모니터링 중단
SELECT index_name, used
FROM v$object_usage
WHERE index_name='IDX_EMP_ENAME'; -- 사용유무 확인- 인덱스 Rebuild하기
ANALYZE INDEX idx_inxtest_no VALIDATE STRUCTURE;
인비저블 인덱스(Invisible Index) * 오라클 11g부터 사용가능*
(인덱스 사용유무 모니터링 기간이 잘못되었다든지 해서) 인덱스를 삭제했는데, 나중에 생각지도 못했던 부분에서 문제가 발생할 수도 있음
- 오라클 11g부터는 인덱스를 실제 삭제하기 전에 “사용안함”상태로 만들어서 테스트를 해볼수 있는 기능을 제공한다.
- 인비저블 세팅하기
> ALTER INDEX idx_emp_sal INVISIBLE;
'프로그래밍 도서' 카테고리의 다른 글
| [오라클 DB 스터디] PL/SQL - 1 (0) | 2025.02.16 |
|---|---|
| [오라클 DB 스터디] 서브쿼리 (0) | 2025.02.02 |
| [오라클 스터디] DML (0) | 2024.12.15 |
| [오라클 스터디] DDL 명령과 딕셔너리 (0) | 2024.12.09 |
| rollup과 cube의 차이 (0) | 2024.11.26 |





댓글 영역